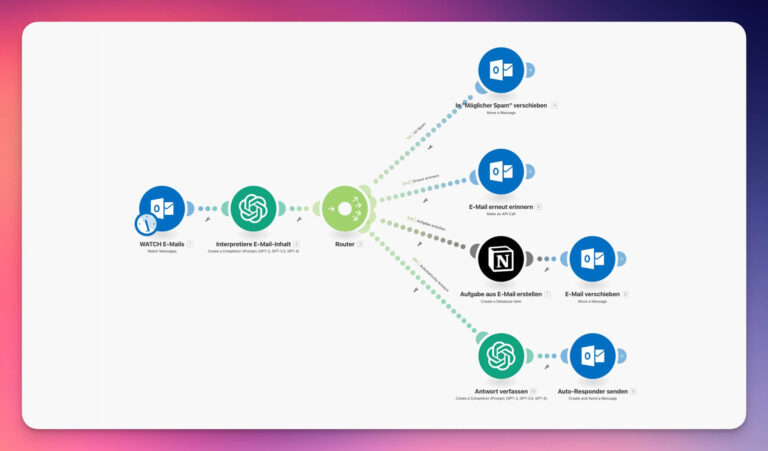
In der Welt der Künstlichen Intelligenz stehst du heute vor einer entscheidenden Wahl: Nutzt du die enorme Power öffentlicher Giganten oder baust du dir deine eigene, private Wissenszentrale? Da ich Unternehmen helfe, 20 % schneller zu werden, ist die Wahl der richtigen Architektur das Fundament für echte Hyperautomatisierung. In diesem Artikel schauen wir uns an, welche KI was kann, wie du deine Daten schützt und wie du technisch eine eigene Lösung hochziehst.
1. Wer kann was? Die Qual der Wahl bei den Modellen
Neben den bekannten Größen haben sich weitere Player etabliert, die für deine Workflows entscheidend sein können:
- ChatGPT: Dein Allrounder für fast alles. Ideal für kreatives Schreiben und schnelle Analysen.
- Claude: Mein Favorit für lange, komplexe Dokumente und insbesondere fürs Coding. Claude schreibt „menschlicher“ und halluziniert seltener bei komplizierten Anweisungen.
- Perplexity: Vergiss Google. Wenn du tiefgehende Recherche mit echten Quellenangaben brauchst, ist Perplexity dein Tool. Es ist eine KI-Suchmaschine, die das Netz in Echtzeit durchforstet.
- Mistral: Der Stolz aus Europa. Mistral bietet extrem effiziente Open-Source-Modelle, die oft weniger Rechenpower brauchen als die US-Konkurrenz und sich hervorragend für den eigenen Betrieb eignen.
- Grok: Wenn du Echtzeit-Daten von X (Twitter) brauchst, um Trends zu scannen, bevor sie in den Nachrichten landen, ist Grok unschlagbar.
- Microsoft Copilot: Die logische Wahl, wenn du tief im Microsoft-Ökosystem (Word, Excel, Teams) steckst. Er greift direkt auf deine Arbeitsdateien zu.
- Google Gemini: Durch das riesige Kontextfenster (bis zu 2 Millionen Token) kannst du der KI ganze Code-Bibliotheken oder stundenlange Videos als Referenz geben.
2. Die Datenschutz-Falle: Was mit deinen Daten wirklich passiert
Ein kritischer Punkt bei jeder Automatisierungsstrategie ist die Frage: Was passiert mit dem Wissen, das du der KI anvertraust? Wenn du die kostenlosen oder normalen Plus-Versionen von ChatGPT und Co. nutzt, musst du davon ausgehen, dass deine Eingaben standardmäßig dazu verwendet werden, die Modelle weiter zu trainieren. Das bedeutet im schlimmsten Fall: Ein interner Prozess, den du heute optimierst, könnte morgen als Antwortvorschlag bei deinem Konkurrenten auftauchen.
Um zu verhindern, dass dein wertvolles Unternehmenswissen im allgemeinen Wissen der KI landet, gibt es zwei goldene Regeln. Erstens: Nutze Enterprise-Lizenzen oder den Zugriff über die API (Schnittstelle). Bei der API-Nutzung garantieren Anbieter wie OpenAI oder Anthropic, dass deine Daten eben nicht für das Training genutzt werden. Zweitens: Etabliere klare Richtlinien für dein Team. Bevor Daten an eine öffentliche KI gesendet werden, sollten sie anonymisiert werden (PII, Personally Identifiable Information, entfernen). Ein cleverer Workflow innerhalb des AXIOM Frameworks sorgt dafür, dass sensible Infos automatisch gefiltert werden, bevor sie die Schnittstelle verlassen. So nutzt du die Intelligenz der Modelle, ohne die Kontrolle über deine Geschäftsgeheimnisse zu verlieren.
3. Der Weg zur eigenen KI
Wenn du absolute Souveränität willst, führst du dein eigenes Modell inhouse oder auf einem dedizierten Server aus.
So setzt du deinen Server auf (Kurzanleitung)
- Hardware: Besorge dir einen Server mit mindestens einer Nvidia GPU (z.B. RTX 4090 für den Start). Installiere Ubuntu Linux als Betriebssystem.
- Docker: Installiere Docker.
- Ollama installieren: Das ist das einfachste Tool, um Modelle lokal zu betreiben. Ein Befehl im Terminal genügt: curl -fsSL <https://ollama.com/install.sh> | sh
- Modell starten: Tippe ollama run llama3.2, und schon läuft die KI auf deiner eigenen Hardware mit 3B Parametern.
- Interface: Installiere via Docker die Open WebUI, um eine Benutzeroberfläche zu haben, die sich wie ChatGPT bedienen lässt.
Fachbegriffe für den Profi-Betrieb
Wenn du dich tiefer mit inhouse KIs beschäftigst, wirst du auf diese Begriffe stoßen, die für deine Performance entscheidend sind:
- RAG (Retrieval-Augmented Generation): Statt die KI mühsam neu zu trainieren, gibst du ihr eine digitale Bibliothek an die Hand. Die KI sucht bei einer Anfrage erst in deinen Dokumenten und antwortet basierend auf diesen Fakten.
- Embeddings: Deine Texte werden in mathematische Vektoren (Zahlenreihen) umgewandelt. Nur so kann die KI Ähnlichkeiten zwischen deiner Frage und deinen Dokumenten verstehen.
- Vector Database (Vektor-Datenbank): Hier speicherst du diese Embeddings (Tools wie ChromaDB oder Pinecone). Sie ist das „Langzeitgedächtnis“ deines RAG-Systems.
- Quantization (Quantisierung): Damit große Modelle auf kleinerer Hardware laufen, reduziert man die Präzision der Berechnungen (z.B. von 16-Bit auf 4-Bit). Das spart massiv Speicher bei minimalem Qualitätsverlust.
- Inference (Inferenz): Der eigentliche Moment, in dem die KI „denkt“ und eine Antwort generiert.
- Context Window: Die Menge an Informationen, die die KI gleichzeitig „im Kopf“ behalten kann. Ist es zu klein, vergisst sie den Anfang deines Dokuments.
- Tokens: Die Währung der KI. Ein Wort besteht oft aus 1-2 Token. Deine Kosten und die Verarbeitungsgeschwindigkeit hängen fast immer von der Token-Anzahl ab.
- Temperature: Ein Parameter zwischen 0 und 1. Bei 0 ist die KI streng faktisch (gut für Buchhaltung), bei 0.8 wird sie kreativ und „mutig“.
- Epoch (Epoche): Ein Begriff aus dem Training. Er beschreibt einen kompletten Durchlauf durch den gesamten Trainingsdatensatz.
4. Welcher Weg passt zu deinem Unternehmen?
Damit du nicht lange rätseln musst, welche Strategie für deine aktuelle Situation die richtige ist, habe ich dir hier eine Entscheidungshilfe zusammengestellt. Je nachdem, wie groß dein Team ist und wie sensibel deine Daten sind, ändert sich die Marschrichtung.
| Strategie | Wer sollte das machen? | Wann ist das der richtige Weg? | Aufwand & Kosten |
|---|---|---|---|
| Public AI (Web-Interface) | Solopreneure, Freelancer, kleine Teams zum Brainstorming. | Wenn keine Kundendaten oder Firmengeheimnisse verarbeitet werden und Schnelligkeit vor Datenschutz geht. | Minimal: 0 € – 30 € / Monat pro User. |
| API-basierte Lösungen | Startups, Agenturen, KMU, die Workflows automatisieren wollen. | Wenn du KI in Tools (Make, n8n, Notion, eigene Apps) integrieren willst und rechtlich abgesicherten Datenschutz (kein Training) brauchst. | Mittel: Pay-per-Token (Abrechnung nach Nutzung). |
| Hybrid / Managed Cloud | Wachsende Unternehmen mit IT-Affinität, aber ohne eigene Server-Hardware. | Wenn du eigene Modelle (z. B. Mistral) kontrollieren willst, aber die Hardware-Wartung lieber Profis in der Cloud überlässt. | Mittel bis Hoch: Monatliche Servermiete (GPU) ab ca. 500 €. |
| Full Inhouse (On-Premise) | Konzerne, Behörden, Unternehmen mit extrem sensiblen IP-Daten oder strenger Compliance. | Wenn absolut kein Byte das Haus verlassen darf und du volle Kontrolle über die Latenz und die Datenhoheit brauchst. | Hoch: Einmalig Hardware (ab 5.000 €) + laufende Wartung und Fachpersonal. |
Mein Tipp für dich
Für die meisten Unternehmen, mit denen ich im AXIOM Framework arbeite, ist der API-Weg oder die Hybrid-Lösung der Sweet Spot. Du bekommst die Intelligenz der besten Modelle der Welt, genießt aber durch die API-Schnittstellen bereits einen professionellen Datenschutz, ohne direkt eine eigene Server-Farm aufbauen zu müssen. Erst wenn du wirklich spezialisierte, interne Dokumente in riesigem Stil per RAG auswerten willst und die Datenhoheit dein höchstes Gut ist, lohnt sich der Schritt zum eigenen Inhouse-Server.
Egal für welchen Weg du dich entscheidest: Wichtig ist, dass du jetzt eine Strategie festlegst, bevor dein Team sich eigene (unsichere) Schatten-IT-Lösungen sucht!
Stay automated,
Georgios